thinking without thinking

"생각한다는 것은 무엇인가?" 이 질문은 철학자들이 수천 년간 씨름해온 명제다. 그런데 2025년 11월 17일, xAI가 발표한 Grok 4.1은 이 질문에 흥미로운 답을 제시했다. 명시적인 추론 과정을 거치지 않고도, 다른 모델들이 수천 개의 토큰을 사용해 사고 과정을 전개한 것보다 더 나은 결과를 내놓은 것이다.
LMArena 텍스트 아레나 리더보드에서 Grok 4.1의 Non-Reasoning 모드는 1465 Elo로 2위를 차지했다. 놀라운 점은 이 점수가 Claude Sonnet 4.5, GPT-4.5, Gemini 2.5 Pro 등 다른 최신 모델들의 전체 추론 점수보다 높다는 사실이다. 즉, Grok 4.1은 단 한 번의 순전파로, 다른 모델들이 복잡한 사고 연쇄를 전개하며 도달하는 지점을 넘어섰다.
The Era of Test-Time Compute
이 이야기를 이해하려면, 먼저 2024년 후반부터 본격화된 추론 모델의 등장을 살펴보아야 한다. OpenAI의 o1 시리즈(2024년 9월), DeepSeek-R1(2025년 1월), 그리고 Qwen의 QwQ가 연이어 등장하며 새로운 접근법을 제시했다. 이들은 모두 같은 핵심 아이디어를 공유한다:
답을 내기 전에 "더 오래 생각하면" 더 나은 결과를 얻을 수 있다는 것이다.
전통적인 대규모 언어 모델은 프롬프트를 받으면 즉시 답변을 생성한다. 하지만 추론 모델은 내부적으로 Chain-of-Thought을 생성하고, 실수를 인식하고, 다른 접근법을 시도하며, 최종 답변에 도달하기 전에 수천 개의 "추론 토큰"을 사용한다. 이것이 바로 "Test-Time Compute"의 핵심이다. 모델의 크기나 학습 데이터가 아니라, 추론 시점에 투입되는 계산량이 성능을 좌우한다는 새로운 확장 법칙(new scaling law)이다.
실제로 효과는 놀라웠다. AIME 2024(미국 수학경시대회) 문제에서 전통적인 모델들이 30% 미만의 정답률을 기록할 때, 추론 모델은 50~80%의 성공률을 보였다. OpenAI의 o1은 79.8%를, DeepSeek-R1은 유사한 수준을 달성했다. 수학, 코딩, 과학적 추론이 필요한 복잡한 문제에서 추론 모델은 확실히 우위를 점했다.
하지만 여기에는 명백한 상충 관계가 있다. 추론 토큰은 비용이다. 사용자는 더 긴 응답 시간을 견뎌야 하고, 서비스 제공자는 더 많은 컴퓨팅 자원을 소비한다. 게다가 모든 질문이 복잡한 추론을 요구하는 것은 아니다. "오늘 날씨가 어때?"라는 질문에 3000개의 추론 토큰이 필요할까?
Non-Thinking Mode
바로 여기서 Grok 4.1의 Non-Thinking Mode가 제시하는 답이 흥미롭다. xAI는 Grok 4.1을 두 가지 설정으로 출시했다. Thinking Mode는 명시적인 추론 단계를 노출하며 1483 Elo로 1위를 차지했다. 하지만 정말 놀라운 것은 Non-Thinking Mode다.
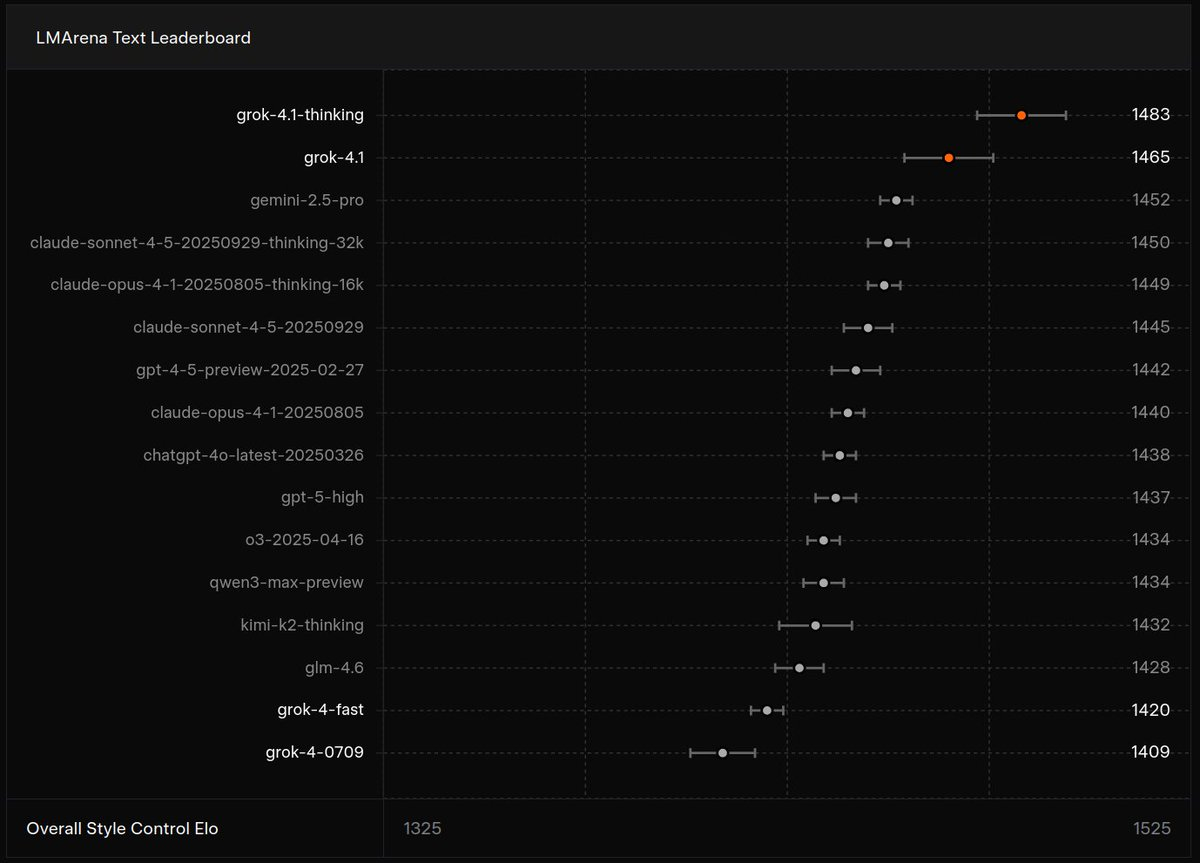
이 모드는 중간 추론 토큰 없이 즉시 최종 답변을 생성한다. 그럼에도 1465 Elo를 기록하며, 다른 모든 모델들의 전체 추론 설정을 능가했다. 이것은 단순한 성능 향상이 아니라 근본적인 질문을 던진다. 추론이 모델 내부에 "암묵적으로" 학습될 수 있다면, 명시적인 추론 토큰이 정말 필요한가?
이 성과는 두 가지 시사점을 갖는다. 첫째, 추론 능력과 추론 과정의 가시화는 별개일 수 있다. Non-Thinking Mode는 추론을 하지 않는 것이 아니라, 그것을 드러내지 않을 뿐이다. 추론 능력은 모델의 가중치에 내재화되어 있고, 순전파 과정에서 암묵적으로 작동한다.
둘째, 이것은 효율성에 대한 혁신적인 개선을 의미한다. Non-Thinking Mode는 Thinking Mode보다 약 28% 빠른 토큰 수준 지연 시간을 보였다. 비용과 속도에서 명백한 우위를 점하면서도, 대부분의 경우 추론 모드에 상응하는 품질을 제공한다. 사용자는 문제의 복잡도에 따라 모드를 선택할 수 있게 된다.
Agentic Reward Modeling
그렇다면 xAI는 어떻게 이것을 가능하게 했을까? 답은 "에이전트 기반 보상 모델링"이라는 새로운 학습 방법론에 있다.
전통적인 인간 피드백 기반 강화학습(RLHF)은 인간 평가자들이 모델의 출력을 평가하고, 이 피드백을 보상 모델로 학습시킨 뒤, 이를 기반으로 정책을 최적화한다. 하지만 이 접근법에는 근본적인 한계가 있다. 인간의 선호는 주관적이고, 일관성을 유지하기 어려우며, 특히 문체, 성격, 감성 지능 같은 "검증 불가능한" 속성을 평가하기는 더욱 어렵다.
xAI는 이 문제를 근본적으로 다르게 접근했다. 그들은 최첨단 에이전트 추론 모델들을 보상 모델로 활용했다. 즉, 최고 수준의 추론 능력을 갖춘 모델들이 수천 개의 응답들을 자율적으로 평가하게 한 것이다. 이 "심판 모델"들은 문체 일관성, 감정 인지력, 사실 기반성, 성격 안정성 같은 복잡한 차원들을 인간보다 더 일관되고 빠르게 평가할 수 있다.
xAI의 공식 발표에 따르면, "우리는 검증 불가능한 보상 신호들을 최적화하기 위해, 최첨단 에이전트 추론 모델들을 보상 모델로 사용하여 대규모로 응답을 자율적으로 평가하고 반복하는 새로운 방법을 개발했다"고 밝혔다. 이것은 단순히 효율성의 문제가 아니다. 이 폐쇄 루프 시스템은 인간이 일관되게 평가하기 어려운 미묘한 기준들을 확장할 수 있게 만든다.
Reasoning Can Be Distilled
Grok 4.1의 접근법은 최근 급속도로 발전한 지식 증류 연구와 흥미로운 연결점을 갖는다. 지식 증류는 원래 큰 "교사" 모델의 지식을 작은 "학생" 모델로 압축하는 기법이었다. 하지만 2024-2025년 들어, 이 분야는 추론 능력의 증류라는 새로운 영역으로 확장되었다.
DeepSeek-R1의 공개는 여기에 있어 중요한 전환점으로 작용했다. 그들은 DeepSeek-R1(6710억 매개변수)의 추론 패턴을 Qwen2.5-7B 같은 훨씬 작은 모델로 증류했고, 놀랍게도 증류된 70억 매개변수 모델이 AIME 2024에서 55.5%를 기록하며 GPT-4(9.3%)를 크게 앞질렀다. 이것은 추론 능력이 모델 크기와 무관하게 전달될 수 있음을 보여준다.
MIT의 Baek과 Tegmark의 2025년 3월 연구 "Towards Understanding Distilled Reasoning Models"는 더 깊은 통찰을 제공한다. 이들은 증류된 모델이 독특한 추론 특성을 개발한다는 것을 발견했다. 이 특성들은 모델을 과잉 사고 모드나 핵심 사고 모드로 조정할 수 있다. 즉, 추론 능력은 단순히 정보를 복사하는 것이 아니라, 모델의 표현 공간에 새로운 구조를 만들어낸다.
특히 흥미로운 것은 "자기 성찰 기능"의 등장이다. 증류된 모델들은 자신의 출력을 평가하고 추론 과정을 모니터링하는 능력을 발달시킨다. 이것은 명시적인 사고 토큰 없이도, 내부적으로 품질 검증이 이루어질 수 있음을 시사한다.
2025년 5월 Chen 등의 "Skip-Thinking" 연구는 더 나아간다. 그들은 모델이 비추론 구간(요약이나 전환 부분)을 자동으로 건너뛰고 핵심 추론 토큰에만 집중하도록 학습시키는 방법을 제시했다. 결과는 놀라웠다. 속도는 빨라지면서도 정확도는 유지되었다. 이것은 "효율적인 추론"이 가능함을 보여준다.
Grok 4.1의 Non-Thinking Mode는 이러한 증류 연구의 정점에 있다고 볼 수 있다. 비록 xAI는 이를 증류라고 명시하지 않았지만, 메커니즘은 유사할 것으로 생각된다. 최첨단 추론 모델들의 판단을 활용한 대규모 강화학습은, 사실상 추론 패턴을 Non-Thinking Mode의 가중치에 "증류"하는 과정이다. 차이점이라면, 교사 모델의 출력을 직접 모방하는 대신, 교사의 평가를 보상 신호로 사용한다는 점이다.
Paradigm Shift: Reinterpreting System 1 and System 2
Grok 4.1이 제시하는 것은 단순한 기술적 혁신을 넘어, AI 시스템의 인지 구조에 대한 새로운 이해를 의미한다. 노벨상 수상자 다니엘 카너먼의 저서 "생각에 관한 생각"에서 제시된 시스템 1(빠르고 직관적)과 시스템 2(느리고 분석적) 사고의 구분을 떠올려보자.
전통적인 대규모 언어 모델은 주로 시스템 1 방식으로 작동했다. 빠르고 직관적이지만, 복잡한 추론에는 약했다. 추론 모델의 등장은 시스템 2를 구현하려는 시도였다. 명시적인 사고 연쇄를 통해 느리지만 정확한 사고를 가능하게 했다.
그런데 Grok 4.1의 Non-Thinking Mode는 제3의 가능성을 보여준다. 시스템 2 수준의 추론 능력을 시스템 1의 속도로 실행할 수 있다는 것이다. 이것은 인간의 전문성이 작동하는 방식과 유사하다. 체스 그랜드마스터는 보드를 보는 순간 "느낌적으로" 최선의 수를 알아챈다. 그들은 수천 시간의 의도적 연습을 통해 시스템 2의 분석적 사고를 시스템 1의 직관으로 내재화했다.
마찬가지로, Grok 4.1은 대규모 강화학습을 통해 추론 패턴을 "컴파일"해서 즉각적인 응답으로 만들어낸다. 이것은 단순히 빠른 것이 아니라, 본질적으로 다른 종류의 능력이다.
Rediscovering Efficiency: A New Phase of Scaling Laws
이러한 발전은 AI의 확장 법칙에 대한 우리의 이해를 다시 한번 바꾸고 있다. 2010년대 중반부터 지배적이었던 Scaling Law 패러다임은 단순했다. 더 많은 매개변수, 더 많은 데이터, 더 많은 연산이 더 나은 성능을 보장했다.
추론 모델의 등장은 Test-Time Compute 라는 새로운 축을 추가했다. 즉, 모델 크기가 아니라 추론 시점의 계산량이 성능을 좌우한다는 발견이었다. 2024년 12월 연구자들은 Llama 3B 모델이 추론 시점 연산을 충분히 활용하면 Llama 70B를 능가할 수 있음을 보였다.
하지만 Grok 4.1은 후속 학습의 효율성이라는 또 다른 차원을 열어준다. 같은 사전학습 기반에서 출발해도, 어떻게 후속 학습을 설계하느냐에 따라 근본적으로 다른 능력을 발현시킬 수 있다. 실제로 여러 증류 연구들이 이를 입증하고 있다. Alibaba의 TinyR1-32B는 DeepSeek-R1 671B와 거의 동등한 AIME 2024 성능을 보였다. 20배 이상 작은 모델이 비슷한 수준의 추론 능력을 갖게 된 것이다. 이것이 가능한 이유는 추론이 단순히 "더 많은 정보"의 문제가 아니라, 올바른 표현 구조를 학습하는 문제이기 때문이다.
Philosophical Reflection: What Does It Mean to Think?
철학자 Gilbert Ryle은 "방법적 앎"과 "명제적 앎"을 구분했다. 자전거를 타는 방법을 아는 것(방법적 앎)은 자전거 타기에 대한 명제적 지식(명제적 앎)과는 다르다. 마찬가지로, 추론을 "할 수 있는" 것과 추론 과정을 "설명할 수 있는" 것은 별개일 수 있다.
Thinking Mode는 "추론을 설명하는 것"에 가깝고, Non-Thinking Mode는 "추론을 수행하는 것"에 가깝다고 볼 수 있다. 전자는 교육적 가치가 있다. 사용자는 모델이 어떻게 답에 도달했는지 이해할 수 있고, 오류를 발견하기 쉽다. 하지만 후자는 효율성 측면의 가치가 있다. 빠르고, 저렴하고, 대부분의 경우 충분하다.
인간의 인지도 마찬가지다. 우리는 대부분의 결정을 내릴 때 의식적인 추론 과정을 거치지 않는다. 하지만 그렇다고 해서 우리가 "생각하지 않는" 것은 아니다. 단지 그 생각이 의식 아래에서, 훨씬 더 효율적으로 일어날 뿐이다.
AI의 발전은 결국 인간 지능에 대한 우리의 이해를 심화시킨다. Grok 4.1이 보여준 것은, 지능이 단일한 현상이 아니라 여러 층위를 갖는다는 것이다. 명시적 추론, 암묵적 추론, 패턴 인식, 직관 - 이 모든 것이 "사고"의 다른 측면들이다